
In today’s world, it goes without saying that information is king. However having a lot of data isn’t just enough. For your information to be accurate and complete, data quality, accuracy and consistency are crucial in ensuring that the results of your analysis are as expected in data mining.
This blog post delves into data quality, its importance, how it impacts data mining, and the tools and techniques to ensure you are working with the best possible information. In short, Clean Data provides clear insights for your business.
What is Data Mining?
Data mining employs complex methods, which are used for data analysis in order to find out some connection between data points. These findings can be a treasure chest for organizations as they offer an opportune to comprehend consumer behavior and plan for the future based on the information acquired.
Let’s say you’re into data mining. You might notice that when people buy product A, they often buy product B, too. This little nugget of information is gold for companies because it helps them create smarter marketing strategies.
Importance of Data Quality in Data Mining
Imagine you are on a treasure hunt. The sand on the beach is full of pebbles and junk, making finding hidden gems a real challenge. Well the same goes for data mining. Data quality which means the correctness, coherence and completeness of data is one of the most important factors to consider when mining data. In a way, if your data is full of errors, gaps, or incoherent entries, your results will be as good as searching for a treasure and finding a worthless pyrite instead.
Data quality management enables the data to be in the right form and free from inconsistencies, thus making them more valuable than a pile of stones. By investing in data quality, you equip yourself with the tools to unearth the hidden treasures within your data truly.
By investing in data quality, you equip yourself with the tools to unearth the hidden treasures within your data and translate them into strategically and meaningfully actionable insights, a valuable skill for aspiring data analysts with an MBA in Data Analytics.
Consider the opportunity to work with the customer database with typos, missing addresses, or outdated information. The resulting insights would be inconclusive and potentially misleading. It is therefore, important to ensure that high quality data is used during the data mining process so as to ensure that the identified patterns and trends are coherent and actionable.
How Can Data Quality Be Improved?
Data quality isn’t a single checkbox or an isolated concept; it’s a more complex concept that ensures your data is fit to be analysed. Data quality management ensures your data is accurate, complete, consistent, and timely, transforming it from raw information into a robust foundation for analysis.
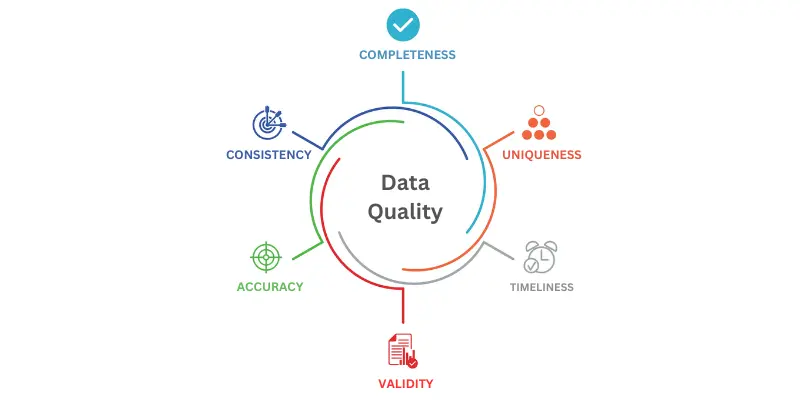
Data quality is not just a one-time check or an isolated concept; it is a more complex concept that needs to be checked and ensured so that your data is ready to be analyzed. Data quality management increases the probability of having accurate data, data completeness, consistency, and timeliness and takes raw information and prepares it for analysis.
Here are six aspects to focus on to improve data quality:
- Accuracy
Does your data accurately reflect reality? Quality data, correct customer addresses, up-to-date product prices, and valid information across all fields.
- Completeness
Are all necessary data points present? Missing information can lead to skewed results.
- Consistency
Does your data follow the same format and definitions throughout? Inconsistent formats create confusion and complicate analysis.
- Validity
Does your data adhere to predefined rules? For instance, are age fields filled with valid birthdates?
- Uniqueness
Are there duplicate entries that could inflate results? Duplicates can skew customer counts or product sales figures.
- Timeliness
Are your data up-to-date and updated as they are recent? Old information on any given topic may lead to wrong decisions.
Although there are many more ideas out there covering aspects in data quality management, these six points form the basis of high data quality and how it can be optimized for data mining purposes. Data quality management means you can make sound data-driven decisions: making data quality investments pay off for your business. Preparing for a move to the next level of data process? If you are out to find management courses near you, known to transform knowledge seekers into job-ready individuals, check out Management Colleges Near Me.
How GDPR Principles Foster Data Quality?
Data quality is one of the principles of GDPR (General Data Protection Regulation). This EU law safeguards data privacy for individuals residing within the European Union (EU) and the European Economic Area (EEA) and regulates the transfer of personal data outside this region. The GDPR emphasises the importance of data quality, mainly when dealing with personal information.
Here’s how the GDPR’s principles influence data quality:
Accuracy
This means that the processing of personal data should be accurate The GDPR prescribes that personal data should be accurate and, where appropriate, originates from the data subject.
Minimisation
The GDPR states that only sufficient and relevant data is collected by businesses and processed for the needful purposes for which it is used.
Transparency
Individuals have the right to access their data and understand how it is used. High-quality data makes it easier for businesses to comply with these transparency requirements.
Data Quality and Proportionality
When these guidelines are applied, one must bear in mind that the GDPR also introduces the concept of data quality and proportionality. This means that in some instances, such a level of data quality is not necessarily indispensable. It is possible for an organisation to devote reasonable resources towards trying to attain optimum dataset quality. The data quality should be directly proportional to the amount of risk relevance that the data poses in everyday usage.
For instance, ensuring high data quality for financial transactions is crucial to avoid cases of fraud. However, data quality requirements for less sensitive information, like user preferences for a music streaming service, might be less stringent. This principle of proportionality ensures that business organizations find a good balance between the interests of data privacy and security and the relevance of high quality data to the performance of organizational tasks.
Data Quality vs Data Governance

Data quality and data governance though have a narrow correlation but are different concepts that revolve around the process of managing business information. Here’s a breakdown to understand the crucial roles they play:
Data Quality
This refers to the inherent characteristics of the data itself. It encompasses aspects like accuracy, completeness, consistency, and validity. Imagine data quality as robust, reliable, and defect-free building materials. High-quality data ensures that the insights gleaned from it are accurate and actionable.
Data Governance
This establishes a framework for managing your data throughout its lifecycle. It defines policies, procedures, and roles to ensure data quality, security, and accessibility. Consider data governance as the blueprint for data quality management – outlining how data is collected, stored, used, and protected. Effective data governance fosters a culture of responsibility and ensures data quality is maintained over time.
Factors Affecting Data Quality
While data’s importance is undeniable, its actual value hinges on data quality. The problem with dirty data, which is contaminated with errors and has elements of inconsistency, becomes a major problem in achieving optimal results of data mining and results in a chain reaction of adverse effects.
Several factors can negatively affect data quality in data mining. Here are some common culprits:
Manual data entry errors
Typos, inconsistencies, and accidental omissions are too common during manual data entry.
Inconsistent data formats
When data from different sources uses different formats (e.g., dates in different formats, varying units of measurement), it can create integration problems and inconsistencies.
Data migration issues
Migrating data from one system to another can lead to missing or duplicated entries if not done carefully.
External data source issues
Data obtained from external sources might have inherent quality problems, such as missing information or inconsistencies in how it’s collected.
Lack of data validation
Errors and inconsistencies can be noticed if data is validated against predefined rules,
Understanding these challenges is crucial for developing prevention strategies and improving data quality.
How To Improve Data Quality?
Data quality is not a one-time fix. It’s an ongoing process that requires vigilance and commitment. Here are some steps you can take to improve data quality in data mining:
- Implement data quality checks throughout your data processing pipelines. These checks can identify errors, inconsistencies, and missing values early on.
- Standardise data formats across different systems. Establish clear guidelines for data format (e.g., date format, units of measurement) to minimise inconsistencies during integration.
- Automating data entry is key to minimizing mistakes. Make use of data capture tools and integration platforms to automate the process and reduce the chances of typos and inconsistencies.
- Ensure your team understands the importance of data quality and follows best practices for data entry. Educate them on how accurate and consistent data entry impacts the overall quality of information.
- Keep a close eye on your data quality metrics through regular monitoring and audits. Track important indicators like data completeness, accuracy, and consistency over time to spot trends and areas that need improvement.
- Invest in data quality tools to streamline the process. Take advantage of data profiling tools, data cleansing software, and data validation tools to automate quality checks and make the whole data management process more efficient.
While data quality is essential, effectively managing it requires a strategic approach. This is where Data Analytics comes into play. Many MBA Available in Colleges in Chennai offer courses in business analytics that equip you with the skills to not only understand data but also design and implement frameworks for data quality management frameworks.
Data Quality for Business Intelligence (BI)
High-quality data is the bedrock of practical Business Intelligence (BI). Inaccurate data can significantly hinder BI efforts, leading to misleading reports and poor decision-making. Here’s how compromised data quality can negatively impact BI:
Misleading Reports
When it comes to BI dashboards and reports, accuracy is key. These tools provide valuable insights into business performance, but if the underlying data is full of errors or inconsistencies, the reports can be misleading.
For example, imagine a sales report that’s based on inaccurate customer data. This could lead to misinterpretations of customer trends, poor decisions when allocating resources, and missed opportunities for sales.
Ineffective Decision-Making
Business leaders rely on BI reports to make informed decisions about finances, marketing strategies, and operational efficiency. By prioritizing data quality, you ensure that your BI reports truly reflect your business performance. This empowers leaders to make well-informed decisions, optimize strategies, and drive business growth.
Data Quality for Artificial Intelligence (AI)
For Artificial Intelligence (AI) to suceed, data quality is absolutely crucial. Machine learning algorithms are trained on data, so if that data is flawed, the resulting models will be unreliable and inherit those flaws.
Let’s take a look at how poor data quality can impact AI initiatives:
Biased Models
AI models trained on biased data can perpetuate those biases in their predictions, leading to discriminatory or unfair outcomes. Just imagine training an AI model to predict loan approvals based on customer data that contains historical biases against certain demographics. The model’s predictions could end up being biased, unfairly favoring or disfavoring certain groups.
Unreliable Predictions
Dirty data leads to unreliable AI models. For instance, let’s say you build an AI model to predict customer churn based on inaccurate customer contact information. The model’s predictions about who is likely to churn would be unreliable, which could result in wasted resources and the potential loss of valuable customers.
Investing in data quality management ensures that you build trustworthy AI models. Clean, consistent, and accurate data empowers AI to deliver reliable predictions, automate complex tasks, and ultimately unlock the true potential of AI for your organization.
Data Quality in Machine Learning
Machine learning models are like precision instruments. Their performance hinges on the quality of the data they are trained on. Data quality remediation is the cornerstone, ensuring your data is clean, consistent, and ready to fuel successful models.
Following are a few methods of data remediation techniques to enhance model performance:
Data cleaning
This process involves removing errors and inconsistencies from your data. This could include fixing typos, correcting data formats (e.g., dates), and handling missing values through imputation techniques. Data quality management ensures your models are trained on a reliable foundation.
Outlier removal
Outliers, data points that fall significantly outside the expected range, can skew your model’s predictions. Identifying and removing these outliers can improve model accuracy and prevent them from unduly influencing the learning process.
Feature engineering
Let’s say you want to create a new feature that better reflects how a specific customer behaves. To do this, you can combine multiple data points. This process is called feature engineering. It helps you extract valuable insights from your data and improve the performance of your models.
By using these techniques to fix data quality issues, you can make your machine learning pipelines more efficient. This ensures that the results they produce are reliable and trustworthy.
If you’re interested in learning how to perform these data quality remediation techniques and kickstart your machine learning projects, consider pursuing an MBA in Data Analytics in Chennai. It will equip you with the skills you need to build a solid foundation for your initiatives.
Now, let’s talk about how we measure data quality. Data quality management is all about making sure your data is accurate, complete, consistent, and up-to-date. But how do we actually measure this quality? That’s where data quality metrics come in.
Accuracy Rate: This metric tells you the percentage of data points that are accurate compared to the total number of data points. In simpler terms, it measures how well your data reflects reality.
Completeness Rate: This metric calculates the percentage of records that have all the required data fields filled in. Incomplete data can hinder analysis and lead to incorrect conclusions.
Duplication Rate: This metric shows you the percentage of duplicate records in a dataset. Duplicates can distort results, skew data analysis, and provide misleading insights.
By keeping an eye on these metrics, you can ensure that your data is of high quality and can be relied upon for analysis and decision-making.
How Data Quality Is Measured?
Data quality management involves the process of making the data accurate, complete, consistent, and timely and converting the raw info into a strong database. But how do we develop a numerical scale that will measure this quality?
Here comes data quality metrics, which can help.
- Accuracy Rate: This metric reveals the precision of the data as the number of correct data points in relation to the total number of data points. In other words, it means to what extent your data accurately represents the real world.
- Completeness Rate: This metric calculates the percentage completeness of records by accounting for the number of records that contain all the data fields that are mandatory. Incompleteness of data may sometimes be a problem in the analysis and can result in wrong conclusions.
- Duplication Rate: This metric gives you the percentage duplication of records from a dataset. Repetition can affect the results, change the direction of the analysis, and cause confusion in the findings. A low duplication rate is beneficial, for instance, in aspects such as data mining as it guarantees the accuracy of the data that is being analyzed.
- Timeliness Rate: This metric calculates the ratio of data points that have been updated within a particular time frame to the total number of data points. Information that is not updated frequently results in wrong decisions being made in business organizations. High timeliness rate means your data is up to date and gives real time picture of your business.
- Validity Rate: This metric measures the compliance of the data with specified rules and constraints by calculating the percentage of points that meet those conditions. A high validity rate is important because it ensures that your data conforms to the recommended standards and there is no possibility of data errors.
For example, through measuring and monitoring these metrics, one is able to assess the general data quality of a given datasets. This allows you to implement data quality management practices and ensure your data is clean, consistent, and ready to fuel successful data mining initiatives.
Ensuring data quality is crucial for any organization that relies on data insights. But what happens when your data is constantly changing? This is where real-time data analysis comes in. Check out our next blog post on Streaming Data Analytics to learn how real-time analytics can unlock the power of your data stream and transform your business!
Data Profiling Tools
Data profiling tools are valuable allies in data quality management. Following are some popular options and their functionalities:
- Open Profiler:The tool must be an open-source tool that offers basic data profiling features that include data type detection, missing value analysis, and frequency analysis.
- Trifacta Wrangler:An interactive data analysis tool with data visualization, data preprocessing, and a connection to other databases.
- Talend Open Studio:An integration and transformation tool with data profiling and ETL (Extract, Transform, Load) tool.
- Informatica PowerCenter: An enterprise-grade data integration platform with built-in data quality features like data profiling, cleansing, and standardisation.
These tools offer varying levels of complexity and functionality. Choosing the right tool depends on your needs, technical expertise, and budget. We will explore more about data profiling in our following blogs. Stay tuned!
Data quality is the cornerstone of successful data mining initiatives. By ensuring your data is clean, consistent, and accurate, you empower yourself to extract valuable insights and make informed decisions. Remember, data is only as good as its quality.
If you’re looking to refine your data skills and gain a deeper understanding of data management, consider pursuing Business Analytics from Top MBA B Schools in Chennai. These programs equip you with the knowledge and expertise to not only leverage data quality tools but also design and implement data-driven strategies within your organization.